 Fraunhofer IAO | Forschungs- und Innovationszentrum Kognitive Dienstleistungssysteme
Fraunhofer IAO | Forschungs- und Innovationszentrum Kognitive Dienstleistungssysteme
KI-Toolbox für Versorgungsunternehmen: Modul KI-Technologien
Die Hintergründe von Künstlicher Intelligenz zu kennen und zu verstehen kann den entscheidenden Vorteil für den erfolgreichen Einsatz von KI in Ihrem Unternehmen darstellen. Dieses Modul ermöglicht einen ersten Schritt und erklärt grundlegende KI-Mechanismen.
Die Künstliche Intelligenz (KI) umfasst ein weites Gebiet an Methoden und Algorithmen. Beachtung und Anwendung findet heute häufig der Teilbereich des Maschinellen Lernens (Machine Learning). Doch weshalb ist Machine Learning für eine Künstliche Intelligenz überhaupt so bedeutsam? Zusätzlich zu Kenntnissen über die Grundlagen des Maschinellen Lernens ist es wichtig, die größten Hürden auf dem Weg zum erfolgreichen Einsatz einer KI- oder Machine Learning-Anwendung zu kennen.
KI-Methoden
KI-Anwendungen wie die Bilderkennung, Sprach- oder Textverarbeitung lassen sich häufig auf grundlegende mathematische Problemstellungen reduzieren, wie die Suche nach optimalen Lösungen eines Problems, das Schlussfolgern aus Wissen oder das Treffen von Entscheidungen auf Basis von Wahrscheinlichkeiten und Regeln. Mit Methoden zur Lösung dieser Problemstellungen lassen sich bereits Probleme wie das Finden der optimalen Route von Berlin nach München oder bei einem Schachspiel die Wahl des nächsten Spielzuges lösen. Voraussetzung ist jedoch die Entwicklung von Algorithmen und die Definition von Wissen und Regeln durch Experten. Dies ist aufwendig und ab einer gewissen Komplexität von Problemen und Daten kaum noch möglich. Effizienter werden diese Methoden, wenn für Probleme kein Lösungsweg vorgegeben wird oder Algorithmen nicht manuell entwickelt werden müssen, sondern wenn Computer die Lösungswege selbst finden und Wissen automatisch angelernt wird. Diesen Schritt kann das Machine Learning leisten.
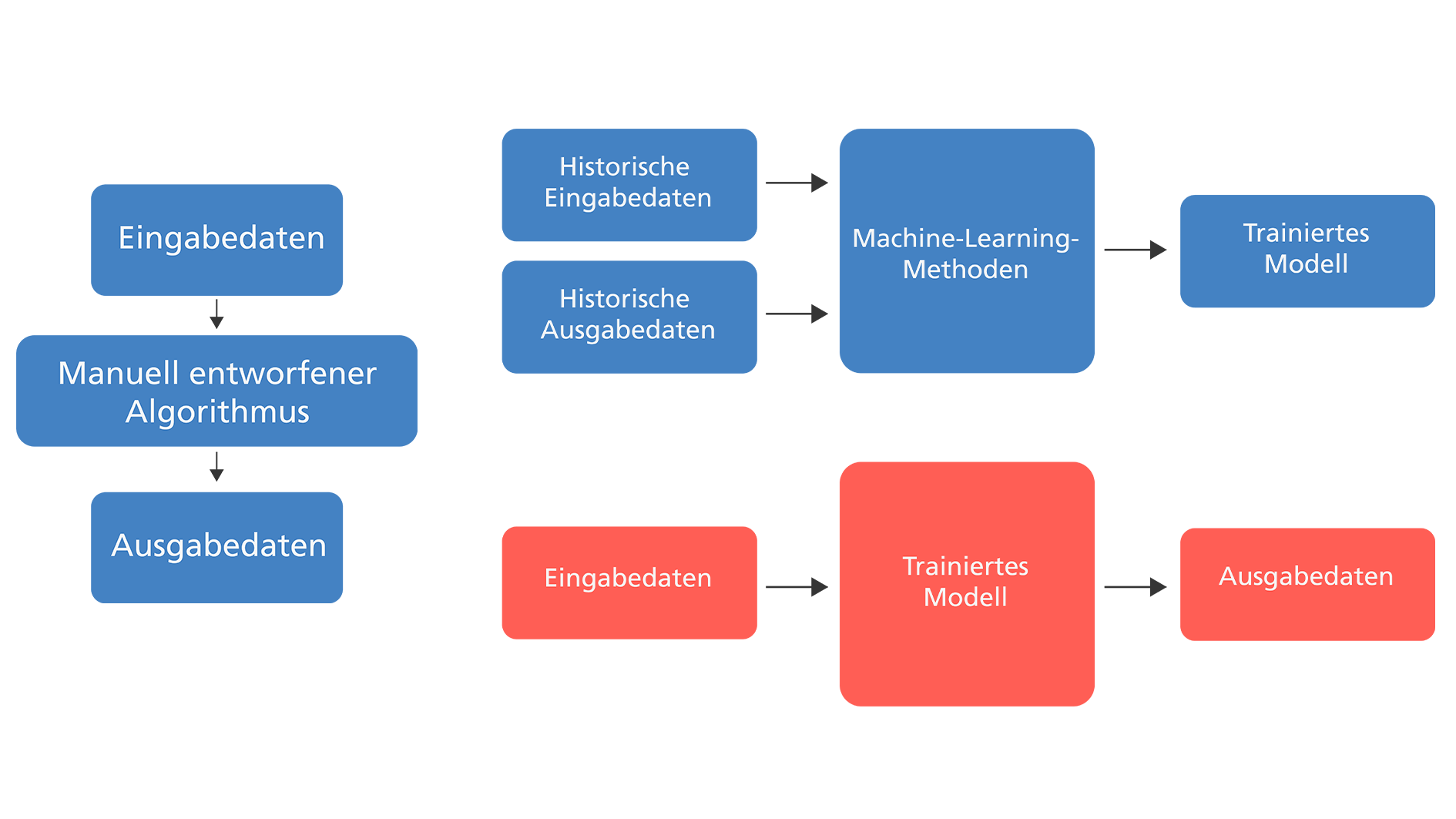
Lernen aus Daten
Machine Learning kann anhand von Daten und Erfahrungen lernen und bietet damit die Basis für technisch fortgeschrittene Projekte in bekannten KI-Anwendungsfeldern wie Sprach- oder Textverarbeitung. Machine-Learning-Methoden versuchen, anhand gegebener historischer Eingangs- und Ausgangsdaten ein Modell zu trainieren, welches Zusammenhänge in den historischen Daten erkennt und in einem zweiten Schritt die erlernte Logik auf neue Daten anwenden kann. Es ist somit nicht mehr notwendig, die Lösung eines Problems in Form eines Regelwerks manuell festzulegen. Dieser Ansatz ist nicht neu; in der heutigen Zeit werden die Methoden des Machine Learning jedoch immer leistungsfähiger, nicht zuletzt aufgrund immer größer werdender Rechenkapazitäten.
Methoden des Maschinellen Lernens
Häufige Anwendungen im Bereich des Machine Learning sind Regressionsaufgaben. Das Ziel ist, anhand der Eingangsdaten die erwarteten Ausgangsdaten möglichst genau zu bestimmen. Dieser Ansatz stellt die Grundlage für Prognosemodelle, wie beispielsweise die zukünftige Parkhausauslastung, dar. In diesem Fall wären die Eingangsdaten beispielsweise die aktuelle Parkhausauslastung und die Ausgangsdaten die prognostizierte Parkhausauslastung.
Eine ebenso weit verbreitete Anwendung ist die Klassifikation. Nach der Anlernphase werden neue Eingangsdaten zuvor festgelegten Klassen zugeordnet. Diese Klassen können Kundengruppen, fehlerhafte oder fehlerfreie Produkte oder aber auch Straßen sein, die gereinigt werden sollten oder nicht. Die Form der Eingangsdaten ist also nicht speziell auf z. B. numerische Werte festgelegt, sondern es können beispielsweise auch Bilder verarbeitet und klassifiziert werden. Eine ebenfalls häufig angewendete Methode des Machine Learning sind Clustering-Algorithmen. Diese können eine Datenmenge in Gruppen strukturieren, beispielsweise in einer Kundendatenbank verschiedene Zielgruppen mit jeweils unterschiedlichen Betreuungsbedürfnissen identifizieren. Viele weitere Anwendungsfälle von KI finden Sie in der Studie »Künstliche Intelligenz anwenden – Einsatzmöglichkeiten und Methoden« oder in der »KI-Toolbox für Macher« speziell für sachbearbeitende Tätigkeiten.
Nachvollziehbarkeit von KI-Methoden
Als Argument gegen eine KI wird häufig die vermeintlich nicht vorhandene Nachvollziehbarkeit aufgeführt. So werden Neuronale Netze als eine Art Black Box dargestellt. Es gibt jedoch auch KI-Methoden, die sehr nachvollziehbar sein können, wie beispielsweise Entscheidungsbäume. Was in diesem Zusammenhang Nachvollziehbarkeit bedeutet, wird anhand des folgenden Beispiels deutlich:
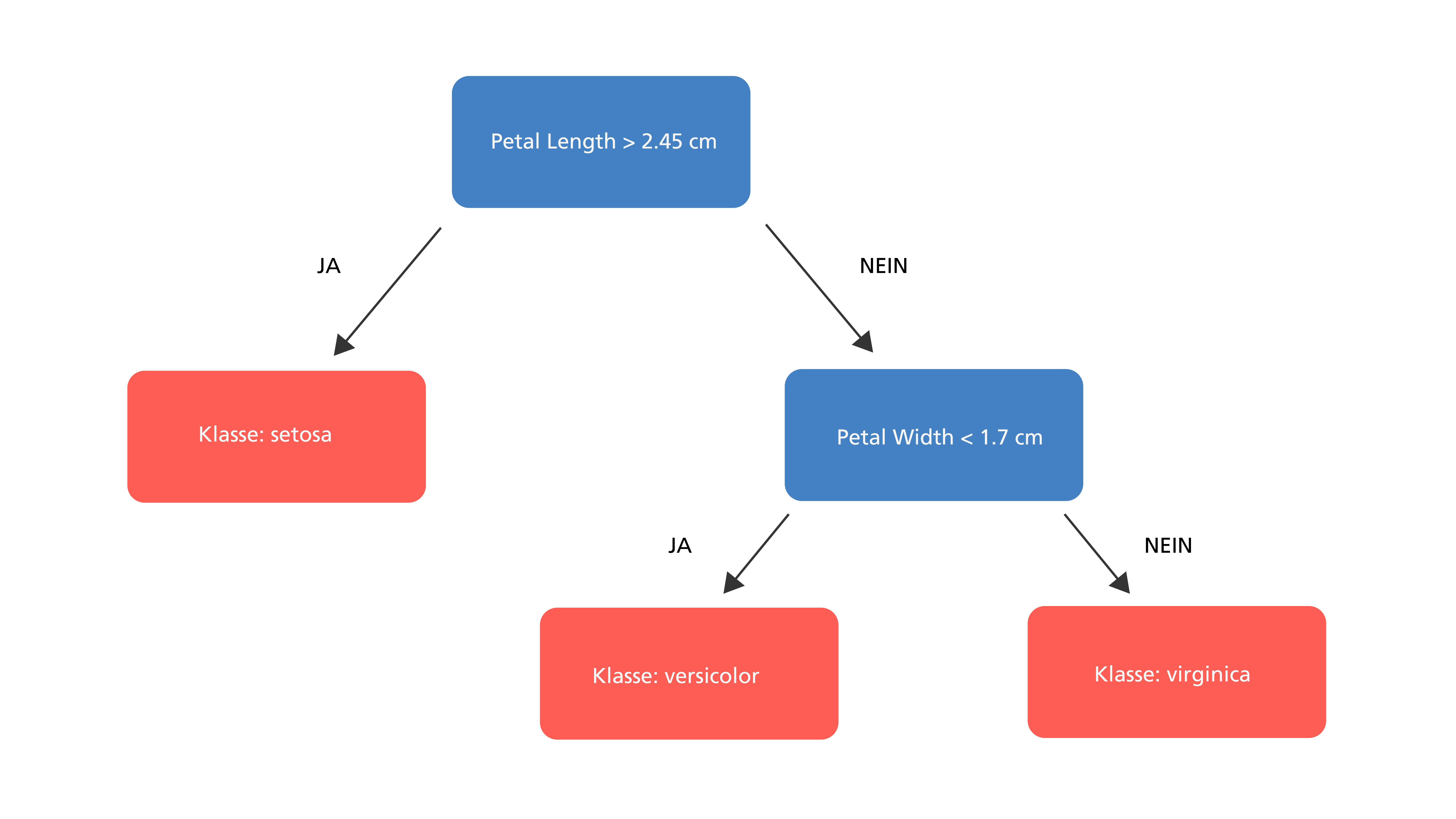
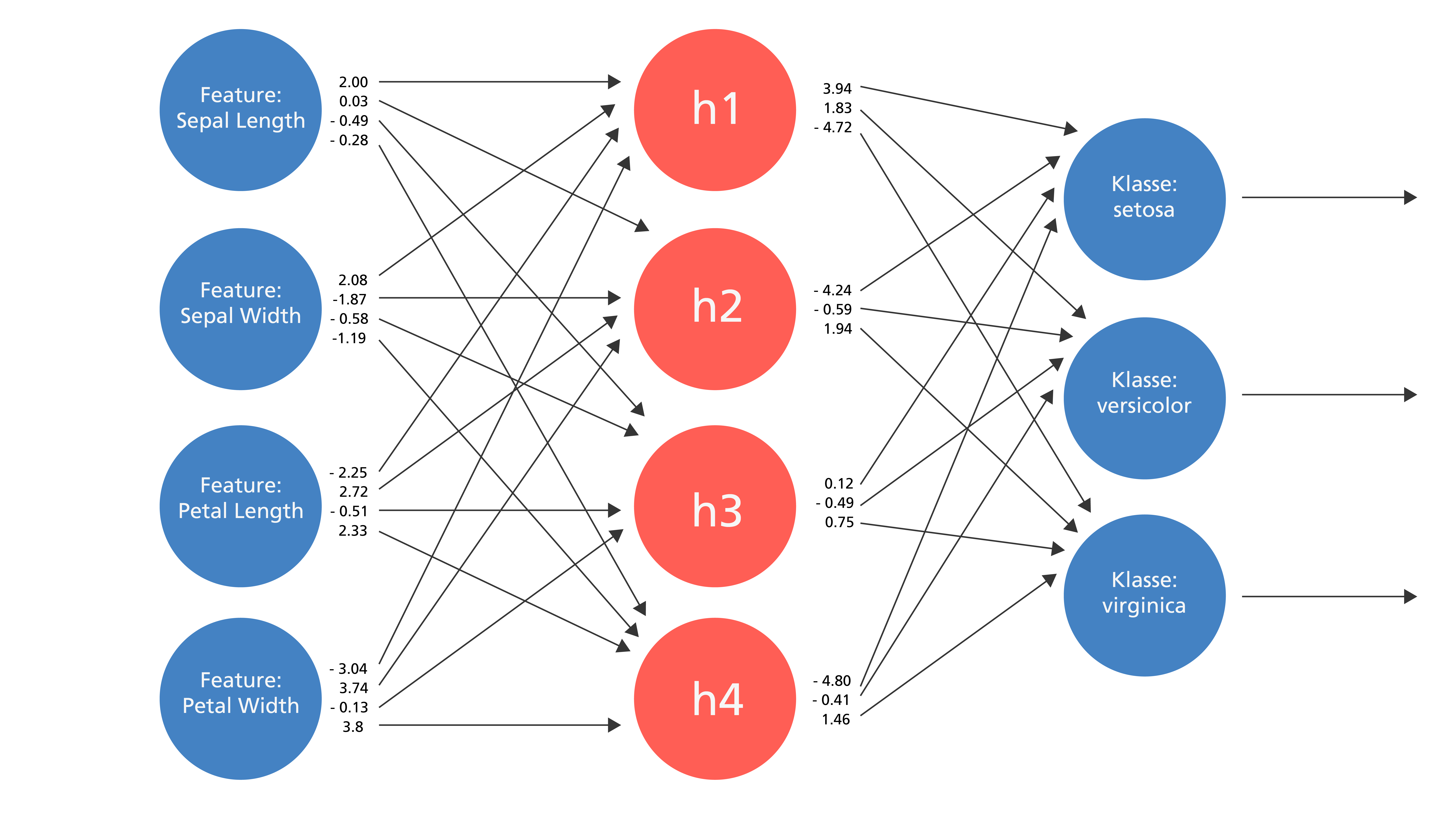
Es wird ein häufig genutzter Datensatz zur Klassifikation von Pflanzen genutzt. Der sogenannte Iris-Datensatz beschreibt anhand von vier Blatteigenschaften jeweils eine von drei Pflanzenarten. Es wird ein Entscheidungsbaum und ein Neuronales Netz darauf trainiert, anhand der Blatteigenschaften die richtige Pflanzenart zu identifizieren. Der angelernte Entscheidungsbaum ist sehr übersichtlich und es wird für Menschen schnell ersichtlich, welche Eigenschaften zu einer bestimmten Klassifikation führen. Dagegen ist das Neuronale Netz sehr kompliziert und für Menschen ist es nicht nachvollziehbar, weshalb bestimmte Daten in eine bestimmte Klasse eingeordnet werden. Ein besseres Klassifikationsergebnis beim Neuronalen Netz (96 % vs. 86 %) muss nicht der maßgebliche Entscheidungsfaktor sein. Die Auswahl von KI-Methoden muss jeweils an die Umstände eines jeden Use Case angepasst werden und neben der Genauigkeit müssen auch Aspekte wie die Nachvollziehbarkeit der Ergebnisse berücksichtigt werden.
Daten als Erfolgsfaktor
Neben der Auswahl der richtigen KI-Methode ist die Selektion der Daten ein wichtiger Faktor für den Erfolg eines Projektes. KI-Methoden können nicht mit beliebigen Daten befüllt werden, sondern es ist eine Vorauswahl und Vorverarbeitung notwendig, die auf jeden Use Case speziell angepasst werden muss. Werden hier ungeeignete Daten genutzt, die nicht der Grundgesamtheit entsprechen, so werden die KI-Methoden keine zuverlässigen Ergebnisse liefern. Im schlimmsten Fall kann eine KI sogar Diskriminierung erlernen. Um dies zu verhindern, müssen die Daten sehr sorgfältig und mit großem Zeitaufwand ausgewählt und aufgearbeitet werden, hierbei sind Branchenkenntnisse von Vorteil. Zusätzlich ist auch die Menge an Daten entscheidend für gute Ergebnisse, in der Regel können mit umfangreicheren Trainingsdaten genauere Modelle entwickelt werden. Die benötigte Datenmenge ist stark von dem einzelnen Use Case und von der Komplexität der Aufgabe abhängig, wobei sich Modelle auch während des Einsatzes durch größer werdende Datenmengen verbessern können.